




什么是数据挖掘和捕捞?
分析简单的“支持平局”策略
为何博彩玩家需要“数猴子”

将数据用作博彩策略的一部分是惯常的做法。然而,尽管某些结果可能看上去很惊人,但是产生这些结果的过程才是关键所在。体育博彩的数据挖掘有哪些问题?继续阅读,找出答案。
在过去几个月中,我在数量可观的网站、博客和论坛帖子上看到人们声称已经寻获了盈利的博彩系统:只需回顾性地将一些看似随意的选择标准应用于大量历史结果和投注赔率的数据集。
在本文中,我调查了通过数据挖掘来搜索有利优势的陷阱:对于体育博彩玩家而言,没有因果性的相关性将带来麻烦。
数据挖掘和捕捞
数据挖掘需要分析大量数据来找出模式和信息。更具体地说,数据捕捞的任务是使用数据挖掘来找出数据中的模式,这些数据具有统计显著性。
我们不能在结果发生之后重新解释原因,因为这会改变事件的因果关系。
体育博彩的数据挖掘和捕捞都非常容易进行。诸多网站上都能找到大量的足球历史结果和投注赔率,它们可以被用于回顾性搜索以及测试盈利的博彩系统。
然而,能够解释这些模式为何可能发生的先验假设通常不会被提出,这一点是将数据挖掘用作数据分析工具的主要限制。
没有因果性的相关性
之前我已经讨论过混淆相关性和因果性以及将准确度和效度与精密度混为一谈的陷阱。如果想要得到有效的博彩系统,让它真正发挥功效,我们首先必须了解让这种博彩系统成功的原因是什么。
除非你在相关性背后建立了因果性,否则你不会知道哪些因素可能会让你的相关性失败——没有因果性的相关性不过是绣花枕头。
英格兰足球乙级联赛中的隐藏价值?
几周前,我的twitter推送上的一些内容吸引了我的注意:如果有人盲目投注在英格兰足球乙级联赛2012/13至2016/17赛季的所有客场取胜上(接近3,000个投注),他能获得的回报让人震惊——Pinnacle(平博)收盘赔率的投注回报高达4.3%,市场最佳赔率的投注回报接近10%。
这五个赛季中只有一个赛季见证了Pinnacle(平博)收盘赔率上的投注损失,而且损失很小。利润图表如下所示:
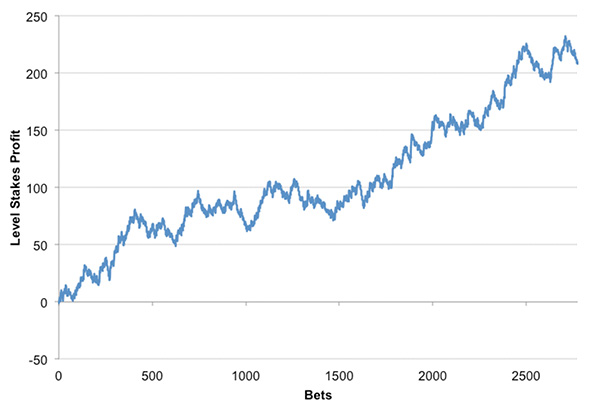
从中可以看出市场低估了这个联赛级别上的客队,就是说他们的赔率价格过高。不过这并不是某种短期失误;相反,看起来这是持续性和系统性的错误——博彩玩家低估了英格兰乙级联赛中客队获胜的可能性,远远超出了博彩公司利润抽水的界限。但是,我们真的能相信在这里找到的信息有任何因果性吗?
支持平局:听上去真简单
最近我还看到了另一种发布出来的策略,叫做“支持平局”。这种策略声称在回顾性测试2012年至今的足球比赛结果和Pinnacle(平博)比赛投注赔率时,2,500个投注带来了接近16%的净利润。
盘口选择标准很简单:两队在过去三场比赛中都没有平局;赔率范围应该为3.20至3.56。测试这个利润的统计显著性之后,我们发现这个记录确实超乎寻常。如果我们假设这个模式只是随机的,那么从这些赔率中得到如此惊人利润的几率可能只有百万分之一或者更低。
- 阅读:如何评价博彩情报商?
让我们想想为什么选择这些特定的标准范围。为什么不是之前四场、五场或者六场比赛?为什么赔率不是3.07至3.41,或者3.13至3.72?没错,我们几乎可以肯定这些标准不是在挖掘数据之前选择的;它们只是数据挖掘之后被发现曾经产出了富有利润的结果。我们不能在结果发生之后重新解释原因,因为这会改变事件的因果关系。
除非你在相关性背后建立了因果性,否则你不会知道哪些因素可能会让你的相关性失败。
如果你想为这种策略辩护,你现在也许会说:“百万分之一的机会:这肯定代表它不是随机的,对吗?” 没错,你说的对。但是如果我们测试一百万种策略,然后发现其中一种和这种一样有统计显著性,意义何在?正如Nassim Taleb在《随机致富的傻瓜》一书中讲述的幻想试图在打字机上重现荷马史诗的猴子那样:
“如果只有五只猴子在打字,那么我会对打出《伊利亚特》的那只猴子刮目相看,甚至可能怀疑它是古代诗人的投胎转世。但如果有十亿只到十亿只的平方那么多的猴子,那就没什么了不起了……”
正如Taleb指出的那样,没有太多人会想到数一数所有的猴子,而且如果他们数了猴子,他们中几乎没有人能总结出值得一提的有趣模式。幸存者偏差让我们只注意到了赢家。
为何博彩玩家需要“数猴子”
如果我们在为了找到盈利模式而捕捞数据之前没有提出先验假设,那么我们应当测试大量的博彩系统以查看找到统计显著性的频率。正如我在我的twitter推送上对这个讨论的回复,“让我们根据10,000种不同的标准选择盲目投注并产生10,000个样本,然后画出它们的收益分布图,看看会是什么样子”。
好吧,我没能找到10,000个合适大小的盲目投注样本——这需要大量的数据——但是我找到了1,686个样本,每个都包含100个投注或者更多。每个样本代表了对单一足球联赛的单一赛季中的某个特定结果(主胜、平局或者客胜)进行盲目投注的赛季。
我首先移除了Pinnacle(平博)的利润抽水以计算每种结果的“真实”价格,然后计算了每个样本的理论回报以及它们的T统计量——我喜欢使用T统计量来测量此类回报有多不可能偶然发生。这些在下方的分布图中标出。正的T分数代表盈利的样本,负数代表损失;数字越大,可能性就越低。
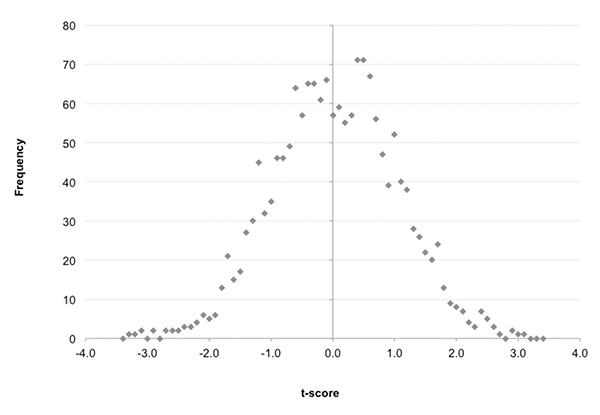
熟悉正态分布(钟形曲线)的读者会将这认作是随机性的证据。也就是说,如果一切都只受到了机会影响,那么这些盲目投注样本的表现非常符合我们期望发生的情况。
- 阅读:如何运用标准偏差进行投注
整体来看,发生的情况几乎没有任何系统性可言。英格兰乙级联赛中那些有利可图的赛季,最有可能不过是瞎折腾数据并撞上了看似盈利的模式而找到的走运表现,其原因是博彩玩家或者博彩公司的不具有系统合理性的行为。
五个赛季加在一起的“真实”赔率回报的T分数为+2.4,暗示结果偶然发生的概率大约为1比100(P值)。这个数据从统计学意义上来看有其显著性,如果我们在不和外界接触的状态下发表相关学术性论文,那么我们会有动力断言它的真实性。但是在更大的全景上进行分析之后,我们知道它几乎肯定不具有真实性,这只是歪打正着的运气而已。
如果我们使用数据捕捞一直到找到有利可图的标准为止,并且以此来着手设计博彩系统,那么我们就有可能无法为我们找到的东西建立因果解释。
事实上,英格兰乙级联赛2007/08赛季样本的表现甚至更好。我拥有数据的242场比赛(12月到5月)显示了超过29%的理论利润(或者移除抽水之后的“真实”赔率的理论利润为35%)。偶然发生如此表现的预期几率为千分之一。这是1,686个样本中表现最好的样本。
正如预期,其中共有837个样本或者大约过半的样本在“真实”赔率上有利可图。在这样的样本例子中,我们自然会预期最好的那个样本显示出大约1比1686的P值。我们预期大约16个样本(或者说大约1%)的P值小于1比100。类似地,我们预期大约168个样本(或者说大约10%)的P值小于1比10。如果数据和上述预期不同,那么我们可以合理地怀疑任何样本是否受到除了运气之外的任何因素的影响。
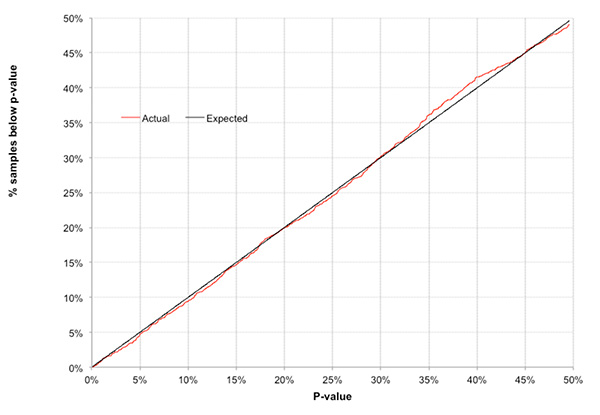
实际上相关数据分别为15(0.9%)和158(9.4%),和我们的预期相当接近。下表中比较了P值在特定阈值下(1比10 = 10%,1比5 = 20%,以此类推)的盈利样本百分比和实际发生百分比的理论预期。很难不注意到几乎完美的等值。
本质上说,图表不过是换了一种方法来说明我们在查看的几乎一切都是因为机会——并且只是因为机会——而发生的。没错,1比1000的概率是令人惊叹不已,但是如果我们的选择范围超过1,000个样本,那么这并不令人意外,因此也不是任何因果关系的有力证据。
博彩玩家可以从数据挖掘和捕捞中学到什么?
足球联赛的赛季利润的分布是随机的,这一点可能在你的意料之外。这绝对不是设计博彩系统的最复杂深奥的方法。但是这一点具有重要意义:如果我们使用数据捕捞一直到找到有利可图的标准为止,并且以此来着手设计博彩系统,那么我们就有可能无法为我们找到的东西建立因果解释。
除非我们可以解释利润的产生原因,否则一切可能只是纯粹的无稽之谈。没有因果性的相关性一定会回归到均值。对于体育博彩玩家而言,这在长远上意味着输钱。
有人可能会辩称,把握住好运气来盈利无可厚非;归根到底,博彩就是为了要赚钱。不过,当我们这么做的时候,我们不应该欺骗自己——认为自己的成功需要归功于其他因素











 据悉,从5月3日起,邱黛国务秘书的遗体被安置在位于金边市堆谷区234号路的家举行葬礼。5月6日将进行土葬。
据悉,从5月3日起,邱黛国务秘书的遗体被安置在位于金边市堆谷区234号路的家举行葬礼。5月6日将进行土葬。

 据柬媒消息,4月8日上午,国家代元首、柬埔寨人民党主席、国王最高顾问委员会主席洪森亲王接见缅甸驻柬大使Kyaw Soe Min。
据柬媒消息,4月8日上午,国家代元首、柬埔寨人民党主席、国王最高顾问委员会主席洪森亲王接见缅甸驻柬大使Kyaw Soe Min。
 据柬媒消息,3月29日,西港云朗基地海军发布消息,3月31日,西港唐岛南部将举行海军实弹演习,请渔民、游客注意,不要在当天经过上述地区,以免发生意外。
据介绍,演习从当天中午12点至下午3点进行,海军将动用3艘军舰和150人,采用14.5毫米机枪发射实弹,另一艘军舰负责清理演习现场。
据柬媒消息,3月29日,西港云朗基地海军发布消息,3月31日,西港唐岛南部将举行海军实弹演习,请渔民、游客注意,不要在当天经过上述地区,以免发生意外。
据介绍,演习从当天中午12点至下午3点进行,海军将动用3艘军舰和150人,采用14.5毫米机枪发射实弹,另一艘军舰负责清理演习现场。
 3月27日公布的一个民意调查结果,约四分之三菲律宾人反对修宪。
在3月初对1200名成年人的民调中,74%说宪法不应在现在或任何其他时间修改。
记者称:“这一意见,在各个地区和各经济阶层都得到大多数人的赞同(分别从69%至82%,和从58%至80%)。”
反对修宪的比例在2024年3月比去年3月大幅上升了43%。
另一方面,在此次最新的调查中,只有8%的受访者说1987宪法现在就应该修改。另有6%受访者反对现在修宪,但支持由现政府在晚些时候修改。
其余的4%受访者对该事项没有特定意见。
3月27日公布的一个民意调查结果,约四分之三菲律宾人反对修宪。
在3月初对1200名成年人的民调中,74%说宪法不应在现在或任何其他时间修改。
记者称:“这一意见,在各个地区和各经济阶层都得到大多数人的赞同(分别从69%至82%,和从58%至80%)。”
反对修宪的比例在2024年3月比去年3月大幅上升了43%。
另一方面,在此次最新的调查中,只有8%的受访者说1987宪法现在就应该修改。另有6%受访者反对现在修宪,但支持由现政府在晚些时候修改。
其余的4%受访者对该事项没有特定意见。















评论 抢沙发